Understanding the Bias-Variance Tradeoff

Understanding the Bias-Variance Tradeoff
Prediction လို့ပြောလိုက်တာနဲ့ Bias နဲ့ Variance တို့က တွဲပြီးပါလာပါတယ်။ Prediction Error တွေကို အကောင်းဆုံးကိုင်တွယ်နိုင်ဖို့ကတော့ Bias နဲ့ Variance ကိုသေသေချာချာ လိုတိုးပိုလျော့ (Tradeoff) လုပ်တတ်ဖို့ပါပဲ။ ဒီလိုလုပ်တတ်သွားမယ်ဆိုရင်တော့ Overfitting နဲ့ Underfitting Error တွေကို ကောင်းကောင်း ကြီးကိုင်တွယ်လာနိုင်မှာပါ။ Let's GO !!
 |
| Bias and Variance ဆက်စပ်ပုံ |
Bias ဆိုတာဘာလဲ
Bias ဆိုတာဗျာ ကျွန်တော်တို့ရဲ့ model က တစ်ခုခုကို predict လုပ်လိုက်တယ်ဆိုရင် ခန့်မှန်းပီးထွက်လာတဲ့ အဖြေနဲ့ ရှိပြီးသား အဖြေမှန် နှစ်ခုကို တိုက်ကြည့်လို့ ရလာတဲ့ ကွာခြားချက်ကို ဆိုလိုတာဖြစ်ပါတယ်။
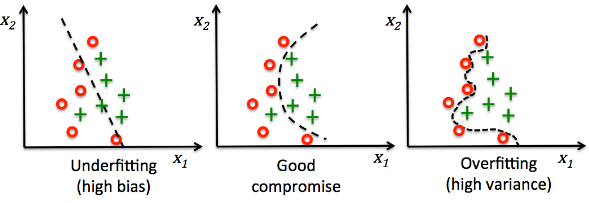
High Bias ဖြစ်မယ်ဆိုရင် ကိုယ့်ရဲ့ model က oversimplify အလုပ်ခံရပြီးတော့ Underfit ဖြစ်သွားပါတယ်။
Variance ဆိုတာဘာလဲ
Variance ဆိုတာက ကျွန်တော်တို့ predict ပြီးထွက်လာတဲ့ အဖြေက variable ဖြစ်နေတာကိုဆိုလာတာဖြစ်ပါတယ်။ variable ဖြစ်နေတာကို ဘယ်လိုပြောရမလဲဆိုရင်.. အမ် .. data တွေက ပြန့်ကျဲနေတာလို့ပြောရမှာ။
High Variance ဖြစ်နေမယ်ဆိုရင် ဘာကိုတွေ့ရမလဲဆိုတော့ ကိုယ့် ထည့်လိုက်တဲ့ တခါမှမမြင်ဖူးတဲ့ data တွေကိုကောင်းကောင်း predict မလုပ်နိုင်တာဖြစ်ပါတယ်။
သူက model training လုပ်နေတဲ့အချိန်မှာတော့ accuracy အရမ်းကိုကောင်းပါတယ်။ အကောင်းလွန်ပြီးတော့ 100 percent accuracy တောင်ဖြစ်နေတတ်ပါတယ်။ ဘယ် machine learing model မှာမှ accuracy 100 ရာခိုင်နှုန်း ဖြစ်မနေရပါဘူး။ Test data ကလည်း predict လုပ်လိုက်တိုင်းလွဲ အဲ့လိုဖြစ်နေရင်တော့ သေချာတယ် overfit ဖြစ်နေပြီ။
overfit ကိုနားလည်အောင်ပြောရင်တော့ model က ဝင်လာတဲ့ data ကိုစဉ်းစားဆုံးဖြတ်နိုင်စွမ်းမရှိတော့တာပါ။
Bulls-eye diagram မှာမြင်သာအောင်ကြည့်မယ်

အပေါ်က diagram မှာကြည့်ကြည့်မယ်ဆိုရင် circle တစ်ခုရဲ့ အလယ်ဗဟို ကတော့ အသင့်တော်ဆုံး perfect prediction point ဖြစ်ပါတယ်။ ကိုယ် predict လုပ်ထားတဲ့ data တွေဟာ စက်ဝိုင်းတွင်းကိုရောက်လေလေ ပိုပြီးတော့ ကောင်းမွန်တဲ့ prediction ကိုပေးစွမ်းနိုင်လေလေ ဖြစ်ပါတယ်။ စက်ဝိုင်းဗဟိုနဲ့ ဝေးသွားရင်တော့ မတိကျတဲ့ အဖြေတွေထွက်လာလေလေ ပေါ့။
Supervised Learning တွေမှာကြုံရတာတွေ
Supervised learning တွေမှာ ဆိုရင် Linear model (feature နှစ်ခုအချိတ်အဆက်ရှိ၊ eg. house price and house location ) တွေသုံးပြီး non-linear data(တစ်ခုနဲတစ်ခု အချိတ်အဆက်မရှိသော data) တွေကို train ခိုင်းမိမယ်ဆိုရင် ကိုယ့်ရဲ့ model က data တွေရဲ့ pattern ကိုရှာမတွေ့ပဲ underfit ဖြစ်နိုင်ပါတယ်။
Supervised Learning တွေမှာပဲ feature (eg. size of house, price of house, etc.) ပေါင်းသောင်းခြောက်ထောင်နဲ့ အရမ်းကို complex ဖြစ်ပြီး noisy (eg. null value တွေ 0 value တွေပါလာခြင်း၊ အများအားဖြင့် data ကောက်လို့မရတဲ့ အခြေအနေတွေမှာ အဖြစ်များ) ဖြစ်တဲ့ dataset ကို train ခိုင်းမိမယ်ဆိုရင်တော့ pattern တွေကိုနားမလည်တော့ပဲ overfit ဖြစ်မှာပါ။
Bias-Variance Tradeoff


ကျွန်တော်တို့ model ကအရမ်းကိုရိုးရိုးလေးပဲ တည်ဆောက်ထားတယ်ထားပါတော့။ Parameters တွေအများကြီးပါတယ့် အပြင် model က high variance and low bias ဖြစ်နေတယ် overfit ဖြစ်နေတယ်ဆိုရင်တော့ ကျွန်တော်တို့ balance ဖြစ်အောင်လုပ်ဖို့လိုလာပြီးဖြစ်တယ်။
Total Error ကိုရှာကြည့်လိုက်ပါတယ်။ Total Error ဆိုတာက ကိုယ့် model ရဲ့ အသင့်တော်ဆုံး bais နဲ့ varianec ကိုရှာတာပါ။ Error ဖြစ်နိုင်ချေအနည်းဆုံးကို ရှာပေးတာပါ။ ပုံလေးကြည့်ကြည့်ပါ။
 |
| finding optimal balance |
Optimal Balance point ကို ရှာတွေ့သွားပြီဆိုရင်တော့ ကိုယ့်ရဲ့ model က overfit လည်းမဖြစ်တော့ သလို underfit လည်းမဖြစ်တော့ပါဘူး။
Bias နဲ့ Variance ကိုနားလည်ခြင်းက Model prediction ကိုကောင်းကောင်းပိုင်နိုင်ခြင်းဖြစ်တာကြောင့် အများကြီးအထောက်အကူဖြစ်စေမှာပါ။
How to prevent overfiting and underfitting ကိုတော့ နောက် post တစ်ခုမှာတင်ပေးသွားပါမယ်။ Stay tuned.
- ကျွန်တော်ရဲ့ရေးသားချက်တွေကိုခွင့်ပြုချက်မရှိပဲ ကူးယူဖော်ပြခွင့်မပြုပါဘူးခင်ဗျာ။


Comments
Post a Comment