K-Nearest Neighbors Algorithm အကြောင်း

K-Nearest Neighbors Algorithm အကြောင်း
KNN Alogrithm ဆိုတာက လွယ်ကူတယ်၊ ရိုးရှင်းတယ် ပြီးတော့ supervised learning မှာသုံးတဲ့ algorithm တစ်မျိုးဖြစ်ပါတယ်။ KNN ကို Classification problems တွေနဲ့ Regression problems တွေမှာတွေ့ရတတ်ပါတယ်။
Supervised Learning အကြောင်းတစေ့တစောင်း
Supervised Learning ဆိုတာ Unsupervised Learning ရဲ့ ဆန့်ကျင်ဘက် ဖြစ်ပါတယ်။ Label တပ်ထားတဲ့ data တွေကိုစက်ကိုနားလည်အောင်သင်ပေးတာ ဖြစ်ပါတယ်။ ဉပမ- ကျွန်တော်တို့ငယ်ငယ်က မိဘတွေက ခွေးပုံလေးတွေ ဝက်ပုံလေးတွေကို ဒါခွေးဖြစ်ပါတယ်၊ ဒါဝက်ဖြစ်ပါတယ် ဆိုပြီး သင်ကြားပေးခဲ့ပါတယ်။ ဒါဟာ supervised learning ရဲ့ နမူနာတစ်ခုဖြစ်ပါတယ်။ အဲ့လိုသင်ပေးလိုက်တော့ ကျွန်တော်တို့က ခွေးကိုမြင်ရင် "ခွေး" ဆိုပြီး သိလာခဲ့ပါတယ်။ စက်ကိုသင်ပေးရာမှာလည်း ထိုနည်းပါပဲ။
 |
| pig |
Classification problem
Classification problem တွေမှာက တိကျတဲ့ အဖြေတွေပါရှိပါတယ်။ ဉပမာ - pizza ပေါ်မှာ နံနတ်သီးထည့်တာ ကြိုက်လေ့ရှိတဲ့ အသက်အရွယ်ကို survey ကောက်ပီး စမ်းသပ်ကြည့်တာပေါ့။ ဒါက classification problem ဖြစ်တာကြောင့် တိကျတဲ့ output ပဲထွက်လာမှာဖြစ်ပါတယ်။ ကြားထဲက မသေချာတဲ့ အဖြေတော့ မထွက်လာပါဘူး။ အောက်က ပုံလေးကို ကြည့်ပီးလေ့လာကြည့်ပါ။ 1 နဲ့ 0 ဆိုပီး ကြိုက်တဲ့အဖွဲ့နဲ့ မကြိုက်တဲ့ အဖွဲ့ဆိုပြီးခွဲခြားပြထားတာဖြစ်ပါတယ်။
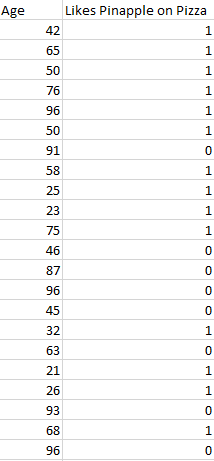
ဒီ classification ဉပမာ မှာဆိုရင် အသက်အရွယ် တစ်ခုကို ရိုက်ထည့်လိုက်တာနဲ့ သူက နံနတ်သီးထည့်တာ ကြိုက်လောက်လားဆိုပြီး ခန်းမှန်းခိုင်းမှာဖြစ်ပါတယ်။
Regression problem
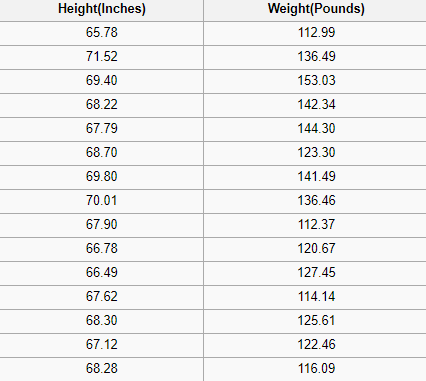
Regression problem မှာကျတော့ ဒသမ တန်ဖိုးနဲ့ value တွေထွက်တဲ့ နေရာတွေမှာသုံးပါတယ်။ အိမ်နေရာကိုကြည့်ပီး house price ကိုခန့်မှန်းတာမျိုးတို့၊ အရပ်ကိုကြည့်ပီး weight ကိုခန့်မှန်းတာမျိုးတို့ ဖြစ်ပါတယ်။ အောက်က ပုံလေးမှာကြည့်လိုက်ပါ။
KNN Algorithm
KNN ကို ရှင်းရှင်းလင်းလင်းနားလည်အောင်ပြောရမယ်ဆိုရင် သူက အနီးနားမှာရှိနဲ့ data တွေကိုလိုက်ကြည့်ပီးတော့ သူတို့နဲ့ နီးရင် သူတို့အဖြစ်ခံယူလိုက်တာလို့ မှတ်ယူလို့ရမယ်။ သူနဲ့ type တူလောက်မယ်လို့ခန့်မှန်းမိတဲ့ သူတွေ စုနေတဲ့ နေရာကို ချဉ်းကပ်သွားတာပေါ့။ Gang တွေလိုပေါ့ ဟဲဟဲ။ ပုံလေးကိုကြည့်ရင်နားလည်သွားမယ်။
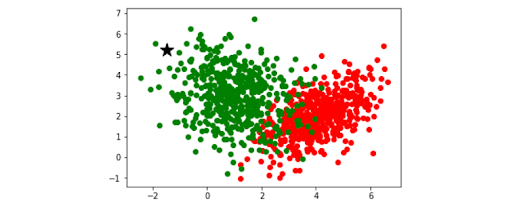
အထက်ပါပုံထဲမှာ ကြယ်လေးရှိတဲ့ နေရာက အစိမ်းတွေစုနေတဲ့ နေရာဆိုတော့ ကြယ်လေးက အစိမ်းလေးလို့ စက်က ယူဆလိုက်ပါတယ်။ အဲ့ဒါကိုဆိုလိုချင်တာဖြစ်ပါတယ်။
Point တွေကြားထဲက distance ကိုတိုင်းလို့ရမယ့် နည်းတွေအများကြီးရှိပါတယ်။ အဲ့ထဲကမှ Euclidean distance ဆိုတဲ့ တိုင်းနဲ့ နည်းက တော်တော်ကို နာမည်ကြီးပါတယ်။
K ရဲ့ တန်ဖိုးကို အတိုးအလျှော့လုပ်ပြီး classification ကိုပိုကောင်းအောင် ချိန်ညှိလို့ရပါတယ်။ K ရဲ့ တန်ဖိုးများလာလေလေ သူ့အနီးအနားက point အများစုကို ဘယ် class တွေလဲကြည့်ပီး မှားမရွေးမိအောင် ပိုသတိပြုလာလေလေဖြစ်ပါတယ်။ K များရင်တော့ အရင်ကထက် နဲနဲပိုကောင်းလာတာဆိုပေမယ့်လက်တွေ့မှာ K များတိုင်းလည်းမကောင်းပါဘူး။ မိမိ problem အတွက်အသင့်တော်ဆုံး K ကိုရွေးနိုင်ဖို့က အရေးကြီးပါတယ်။
အောက်ပါပုံလေးမှာ လေ့လာကြည့်ပါခင်ဗျာ။
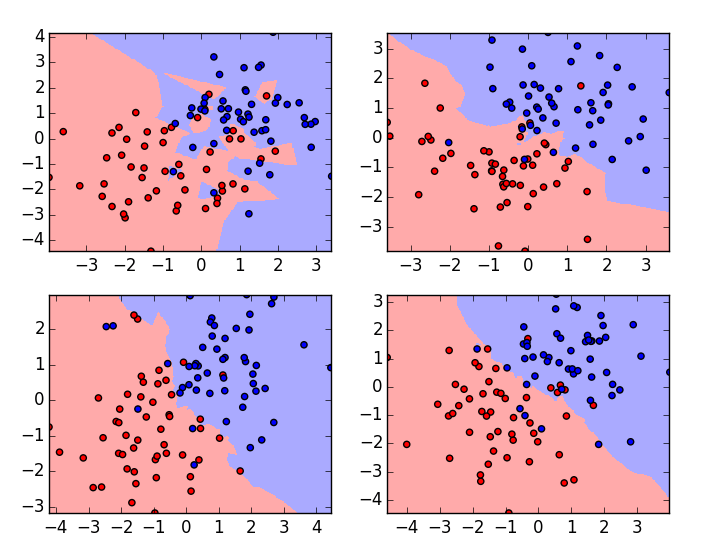
K အရေအတွက်ကို မှန်မှန် ကန်ကန် မထားနိုင်ပဲ အများကြီးထားမိတာတို့ တစ်ခုပဲထားမိတာဆိုရင် ဘယ်ဘက် အပေါ် ကပုံလိုဖြစ်နေမှာပါ။ ထိုပုံဟာ overfit ဖြစ်နေတာကိုတွေ့ရပါမယ်။ ညာဘက်အောက်ဆုံက ပုံသာလျှင် အသင့်တော်ဆုံးပုံဖြစ်ပါတယ်။
KNN အကြောင်းကိုနားလည်မယ်လို့မျှော်လင့်ပါတယ်။


Comments
Post a Comment