Activation Function များအကြောင်း
.jpg)
Activation Function များအကြောင်း
Activation Function တွေကို Transfer Function လို့လည်းခေါ်ကြပါတယ်။ Activation Function တွေကို Neural Network တွေမှာ Node တစ်ခုရဲ့ output ကိုရယူလိုတဲ့ အခါမှာသုံးကြပါတယ်။ Node တွေရဲ့ output ဟာ Activation Function တွေရဲ့ input မဟုတ်လား။
Neural Network တွေမှာ ဘာလို့ activation function ကိုသုံးတာလဲ
Network တွေကနေ ထွက်လာတဲ့ output value တွေကို ဒါကကိုလိုချင်တဲ့ ပုံစံဟုတ်လားမဟုတ်လား စီစစ်တာမျိုးတွေမှာသုံးပါတယ်။ ထွက်လာတဲ့ value တွေကို 0 နဲ့ 1 ကြားထဲကတန်ဖိုးအဖြစ် ပြောင်းလဲလိုက်တာမျိုး၊ တခါတလေ positive value ပဲလိုချင်လို့ပြောင်းပစ်လိုက်တာမျိုး၊ -1 နဲ့ 1 ကြားပဲလိုချင်လို့ ပြောင်းလဲတာမျိုးတွေ အစသဖြင့် အမျိုးမျိုးသုံးကြပါတယ်။
Activation Function ကို နှစ်မျိုးခွဲလို့ရပါတယ်။
(1) Linear Activation Function
(2) Non-linear Activation Function ဆိုပြီး ဖြစ်ပါတယ်။
Linear or Identity Activation Function
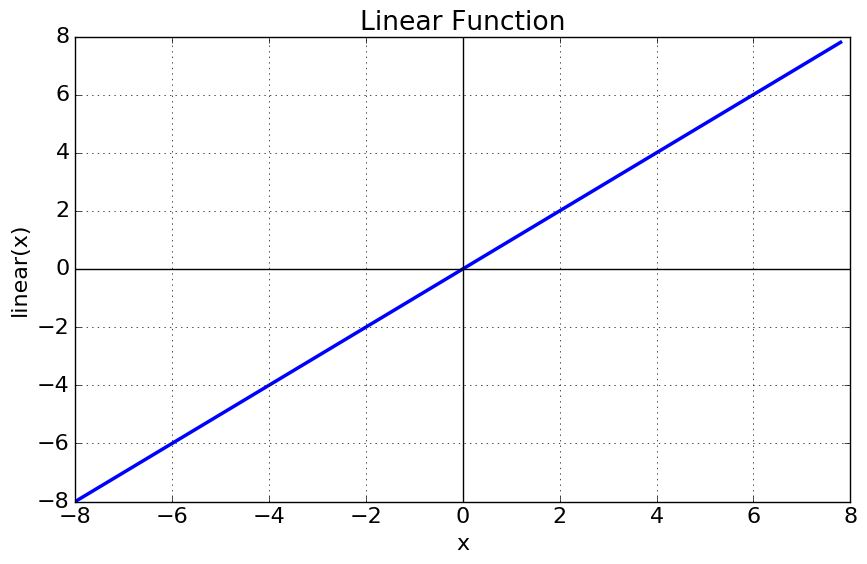
အောက်ပါပုံမှာ မြင်ရတာကတော့ Linear ဖြစ်နေတဲ့ မျဉ်းတစ်ကြောင်း ဖြစ်ပါတယ်။ Output တွေကို ထိုမျဉ်းပေါ်မှာပဲ ဖော်ပြတာဖြစ်ပါတယ်။
 |
| Linear Function |
Equation ကတော့ f(x) = x
Range ကတော့ - inifinity to infinity အထိဖြစ်နိုင်ပါတယ်။
အားနည်းချက်ကတော့ အရမ်း complex ဖြစ်တဲ့ output တွေ နဲ့ non-linear output တွေကို မဖြေရှင်းနိုင်ပါဘူး။
Non-Linear Activation Function
Non-linear activation function တွေကတော့ လူသုံးတော်တော်များကြပါတယ်။ Non-linear ဖြစ်နေတော့ ပုံကအောက်ပါပုံ အတိုင်းထွက်နေတာကို မြင်တွေ့ရမှာပါ။
 |
| non-linear function |
ဒီ function ကတော့ data အများစုနဲ့ ကိုက်ညီနိုင်ပီးတော့ differentiate လုပ်တာမျိုးတွေမှာ အခုလို output မျိုးကိုမြင်တွေ့ရပါတယ်။ ဒါကြောင့်လဲ လူသုံးများပါတယ်။
Non-linear activation function ကိုပိုနားလည်ချင်ရင်တော့
Derivative or Differential (Slope) - x-axis နဲ့ y-axis တို့ရဲ့ပြောင်းလဲပုံကိုသိရပါမယ်။
Monotonic Function - Function ကတိုးလဲမတိုးလာဘူး ငယ်လဲမငယ်သွားတဲ့ function အကြောင်းကိုလဲသိရပါမယ်။
Non-Linear Function တွေထဲမှာမှ သူ့ရဲ့ curve နဲ့ range လိုက်ထပ် ပြီးခွဲခြား ပါသေးတယ်။
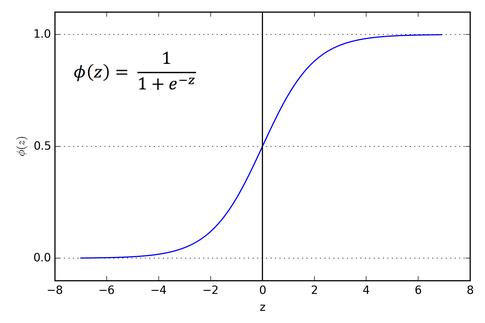
1. Sigmoid or Logistic Activation Function
သူ့မှာတော့ S ပုံစံ curve ပါရှိပါတယ်။
 |
| sigmoid function |
Sigmoid Funtion ကို ဘယ်နေရာမှာသုံးလဲဆိုတော့ ထွက်လာတဲ့ output ကို 0 နဲ့ 1 ကြားဖော်ပြချင်တဲ့ အခါကျရင် သုံးပါတယ်။ Probability ကိုခန့်မှန်းတဲ့ အချိန်မှာလဲဖော်ပြဖို့ သုံးကြပါတယ်။ Probability ဆိုတာက 0 နဲ့ 1 ကြားပဲထွက်တာဆိုတော့ ဒါကိုပဲသုံးကြတာပေါ့။
Function တစ်ခုက differentiable ဖြစ်ရင်သုံးပါတယ်။ ကျွန်တော်တို့ slope တန်ဖိုးကိုရှာလို့ရရင်ပေါ့။
Function ကတော့ monotonic ဖြစ်ပါတယ်၊ ဒါပေမယ့် function ကို derivative တန်ဖိုးရှာလိုက်ရင်တော့ monotonic မဖြစ်တော့ရင်သုံးပါတယ်။
Logistic Sigmoid Function က neural network တွေကို train လုပ်တဲ့အချိန်မှာ ကြာနေတာမျိုးတွေ ဖြစ်တတ်ပါတယ်။
Class တွေအများကြီးကို classify လုပ်မယ်၊ output ထုတ်ချင်တယ်ဆိုရင်တော့ softmax function ကတော့ အသင့်တော်ဆုံးဖြစ်ပါတယ်။
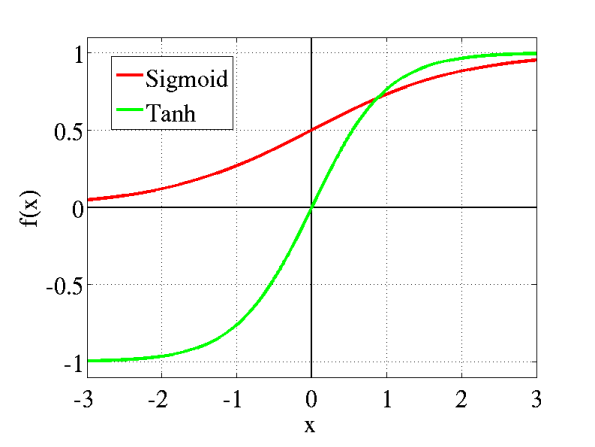
2. Tanh or hyperbolic tangent Activation Function
Tanh function ကတော့ logistic funtion နဲ့ နဲနဲတော့ တူပါတယ်။ ပိုပြီးတော့လည်းကောင်းပါတယ်။ Tanh function ရဲ့ range ကတော့ -1 to 1 ဖြစ်ပါတယ်။ သူလည်း S shape ပါပဲ။
 |
| tanh function |
ဒီ function မှာကောင်းတဲ့အချက်က negative value ပါလာရင်လည်း သူက သေချာ map လုပ်ပေးတာပါပဲ။
Differentialble ဖြစ်တယ်၊ monotonic ဖြစ်တယ် သူ့ derivative က monotonic မဟုတ်ရင်ပေါ့။
Tanh function ကို class နှစ်ခုကို classify လုပ်တဲ့အချိန်မှာ သုံးကြပါတယ်။
Tanh နဲ့ Logistic function နှစ်ခုလုံးက feed-forward network တွေမှာသုံးကြပါတယ်။
3. ReLu(Rectified Linear Unit) Activation Function
ReLu function ကတော့ လက်ရှိကမ္ဘာပေါ်မှာအသုံးများဆုံး function တစ်ခုဖြစ်ပါတယ်။ Convolutional Neural Network နဲ့ Deep Learning တွေမှာတော်တော်ကို အသုံးများတာပါ။
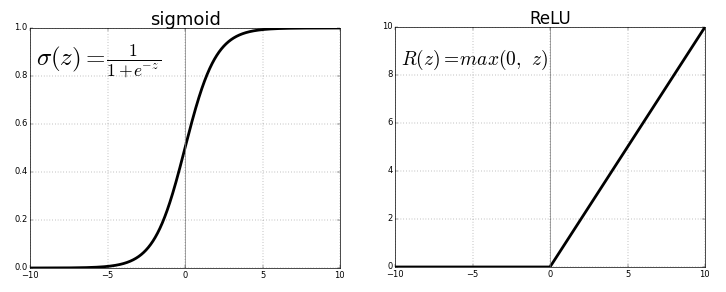 |
| relu function |
ReLu Function က ပုံမှာမြင်တဲ့ အတိုင်းပါပဲ တစ်ဝက်နေစပြီးတော့ ပြောင်းသွားတာဖြစ်ပါတယ်။ R(z) = z ဖြစ်မယ်ဆိုရင် R(z) ရဲ့ တန်ဖိုးဟာ 0 ထက်ငယ်နေမယ်သို့မဟုတ် 0 ဖြစ်နေမယ် ဆိုရင် R(z) = 0 ဖြစ်ပါမယ်။ အနှုတ် တန်ဖိုးမရှိလို့ဖြစ်ပါတယ်။
Range ကတော့ 0 to infinity ဖြစ်ပါတယ်။
Function ကိုယ်တိုင်ရော သူ့ရဲ့ derivative ကရောက monotonic ဖြစ်ကြပါတယ်။
တစ်ချက်တော့ရှိပါတယ် သူ့မှာရှိတဲ့ negative တန်ဖိုးတွေအကုန်လုံးက 0 ဖြစ်သွားတော့ overfit ဖြစ်နိုင်ပါတယ်။
4. Leaky ReLu Activation Function
ReLu ရဲ့ ပြသနာကို ဖြေရှင်းဖို့ Leaky ReLu ကပေါ်လာတာပါ။
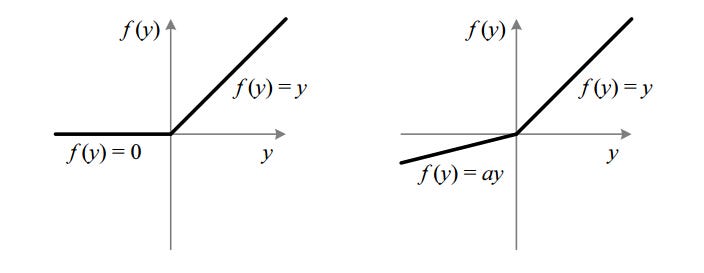 |
| leaky relu function |
Leak ReLu ကတော့ ReLu ရဲ့ range value problem ကိုဖြေရှင်းလိုက်ပါတယ်။ ဒီမှာတော့ a ရဲ့ value ကတော့ 0.01 ဖြစ်နေပါတယ်။ a ရဲ့တန်ဖိုးက 0.01 မဟုတ်တော့ရင်တော့ Randomized ReLu ဆိုပြီးတော့ ခေါ်ကြပါတယ်။
Leaky ReLu ရဲ့ range ကတော့ -infinity to infinity ဖြစ်ပါတယ်။
Leaky နဲ့ Randomized ReLu function နှစ်ခုလုံးဟာ monotonic ဖြစ်ကြပါတယ်။ Derivative တွေလည်း monotonic ဖြစ်ကြပါတယ်။
Derivative/Differentiation တွေကိုဘာလို့လုပ်တာလဲ
Curve ကို update လုပ်ချင်လို့ပါ။ ဘယ် direction ကိုသွားရမယ်၊ ဘယ်လောက်ပြောင်းလဲသွားပြီလဲ၊ slope တန်ဖိုကို update လုပ်မှာမို့လို့ derivative လုပ်တာပါ။ ဒါကြောင့် Machine Learning နဲ့ Deep Learning တွေမှာ derivative ကိုရှယ်တွေ့နေရတာပါ။
အောက်ကပုံကတော့ Activation Function ရဲ့ Cheat Sheet ဖြစ်ပါတယ်။
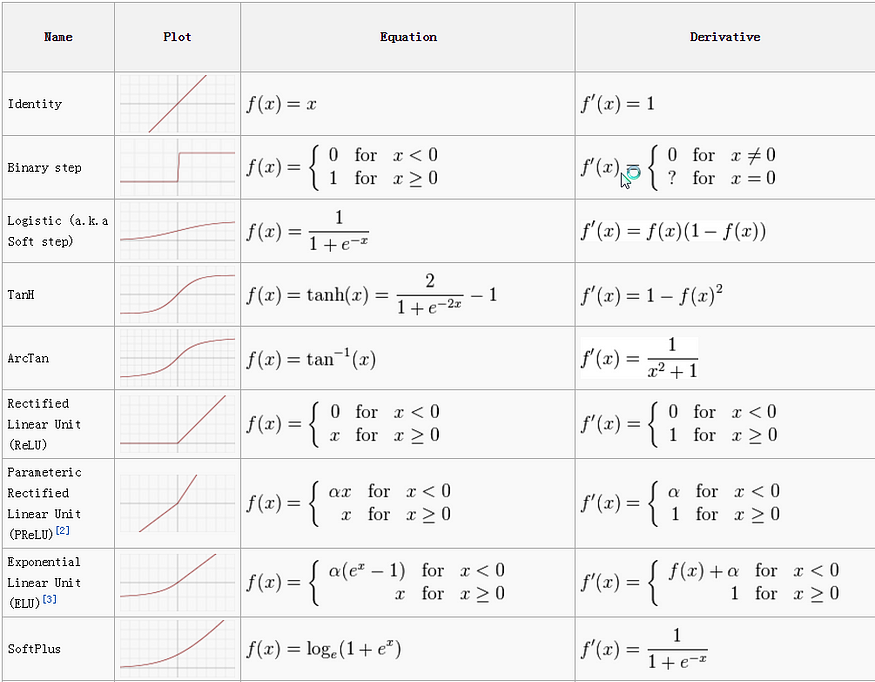 |
| Activation Function Cheatsheet |
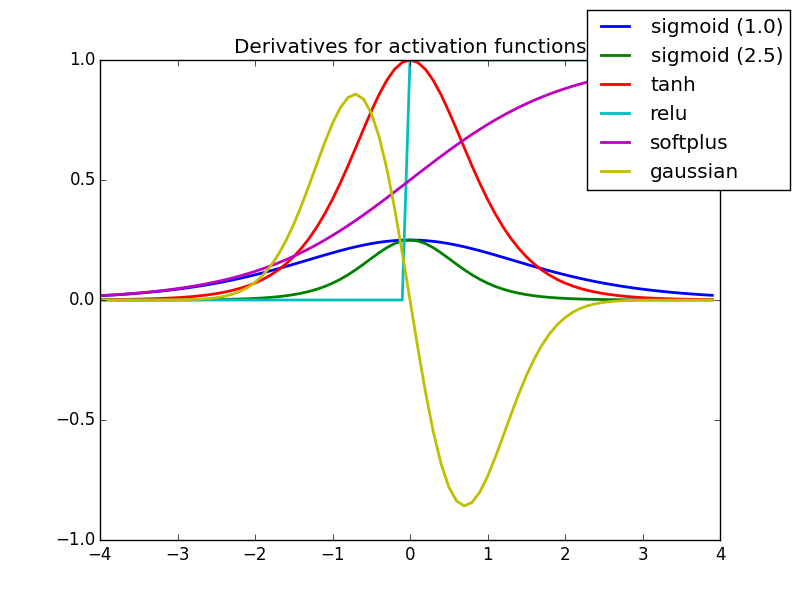 |
| Derivative of Activation Functions |
အပေါ်မှာတော့ လူသုံးများတဲ့ပြီး သိဖို့လိုတဲ့ Activation function တွေကို ဖော်ပြခဲ့တာဖြစ်ပါတယ်။
ဒီရေးသားချက်အား ခွင့်ပြုချက်မရှိပဲ ကူယူဖော်ပြခွင့်မပြုပါ။


Comments
Post a Comment